

Like SLAM (simultaneous localization and mapping), visual SLAM is a camera-based technology that allows a mobile robot to build a map of its environment and to localize itself in this same map. However, it is distinguished by the variety of its applications, which are not limited to autonomous navigation. Indeed, visual SLAM is also the basis of augmented reality. Explanations.
SLAM technologies for mobile & AMR robots
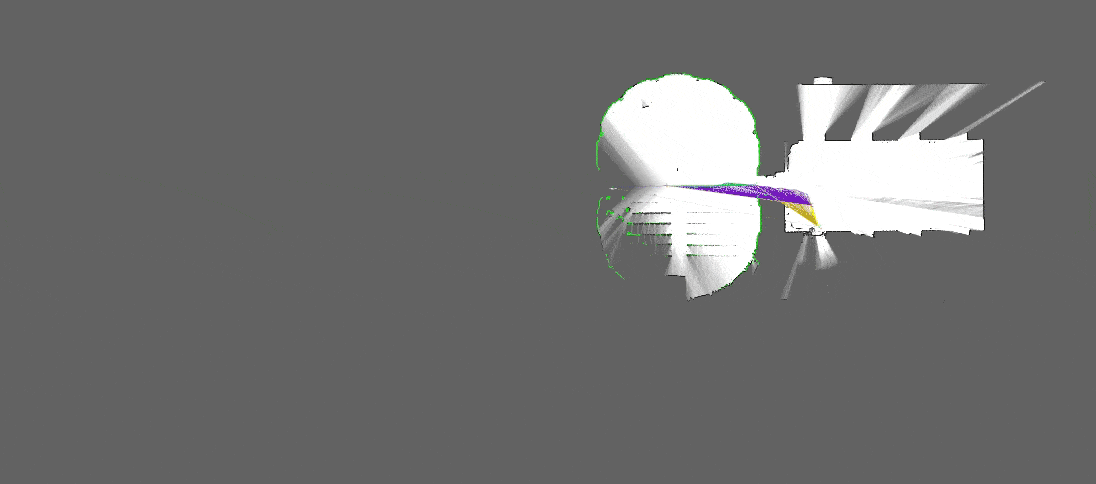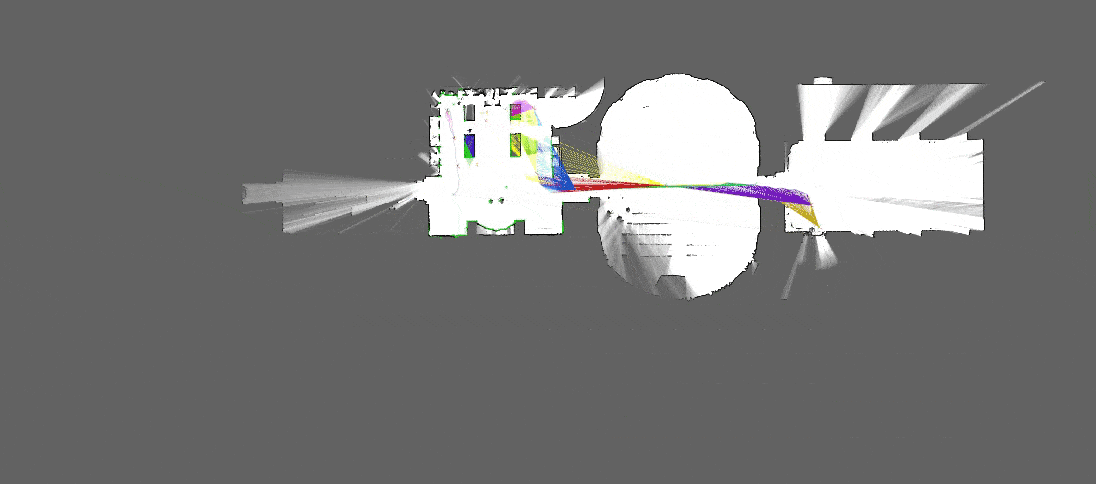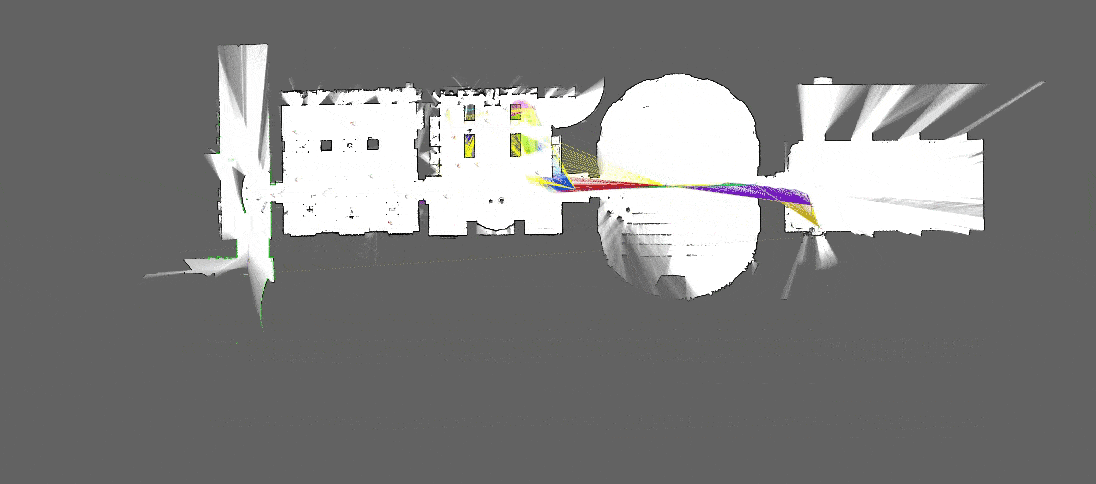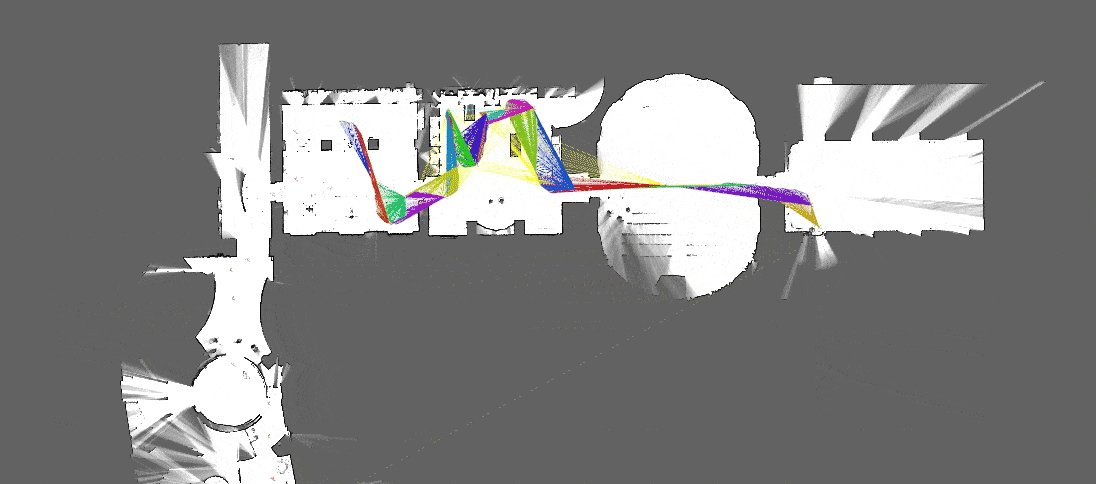
[Source : Google Cartographer]
In order to build a map and to locate itself reliably, a mobile robot needs information about its environment. This information can be obtained :
- either by distance sensors, such as LiDAR, which emits a light and calculates the return time after being reflected by an object, with the aim of deducing the distance between the robot and the obstacle.
- or by cameras, such as simple computer webcams or RGB-D cameras, on which visual SLAM is based.
Visual SLAM: what is the interest for a mobile robot?
The strength of this algorithm lies in the large amount of information obtained: indeed, the images allow to estimate not only the distance of the sensor to the obstacles but also the colors or the intensity of all the pixels that compose it. Thus, the map collected thanks to visual SLAM appears much richer in information compared to a map resulting only from distance sensors. Moreover, cameras (RGB, RGB-D) currently have a relatively low hardware cost compared to LiDARS, which have the advantage of being more accurate in measuring distances.
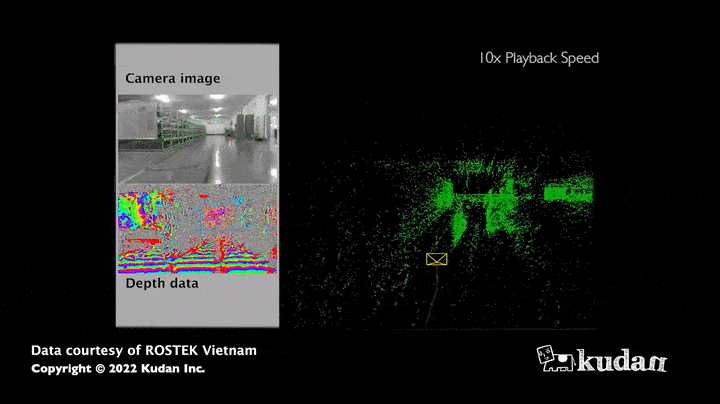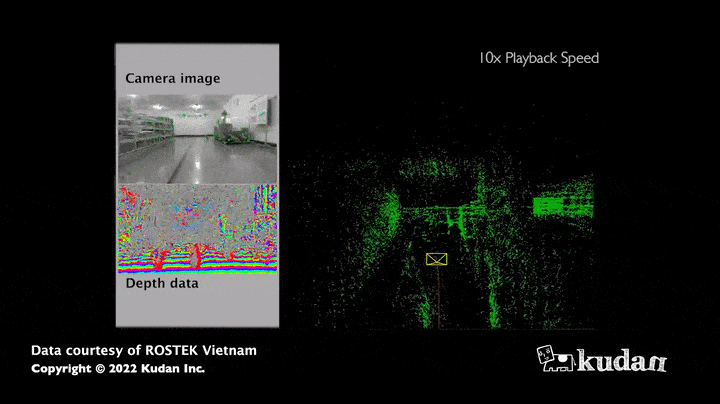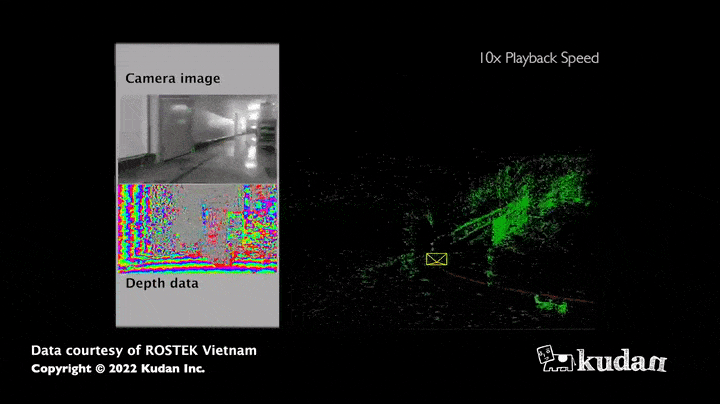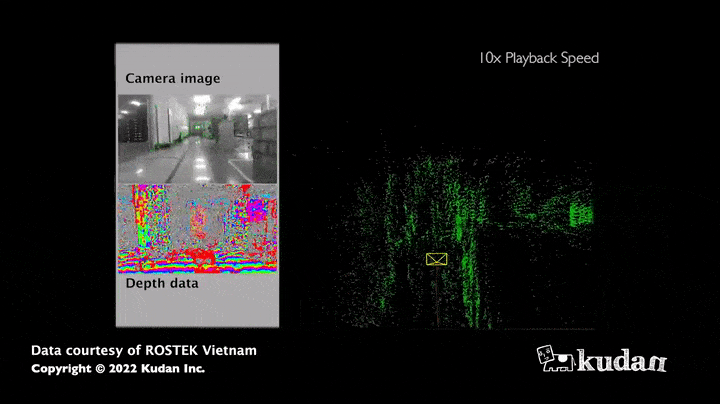
Use case of visual SLAM
Autonomous navigation
The maps obtained thanks to visual SLAM are used to support the movement of AMR (autonomous mobile robots): the principle is to give a destination to the robot, which will then define its trajectory and get there reliably and autonomously by observing its environment using its sensors.

Augmented reality
The principle? Integrate virtual objects in a real environment. And for this, the visual SLAM represents an essential element. It allows to position objects in a place and to find them during a future visit, whether it is with the help of a phone, a webcam, or (soon!) a telepresence robot.

Visual SLAM: feature extraction for augmented reality
Simplified structure of a visual SLAM algorithm

As a starting point for the mapping, the images from the camera are used to estimate the position of the robot in this map: this is done through the localization and mapping module.
To achieve a result in a visual SLAM framework, these two modules need to resort to a preliminary step called feature extraction (visual SLAM purists will understand here our need to drastically simplify the taxonomy of existing methods in a popularization framework). The remainder of this article aims at presenting this step.
Focus on feature extraction
For a smooth understanding, the Awabot Intelligence team offers you a step-by-step explanation based on… cats.
Step 1. Feature detection
Features are interesting, easily detectable and specific areas in an image: they are extracted, then followed from image to image, in order to estimate the camera movement and ultimately its position, while building the map simultaneously. They can correspond to points, textures, contours, which are characterized by strong changes in contrast and light.
Thus, from an image, the first step is to identify them using algorithms.

Step 2. Description of the features
Once the features are detected, they must be described: for each feature there is a vector, i.e. an array of numbers that describes an area of the image (the feature). This array of numbers is also obtained using an algorithm whose goal is to make the description robust to certain variations, such as rotation in the plane or changes in brightness. This description is fundamental to differentiate all the features contained in an image.
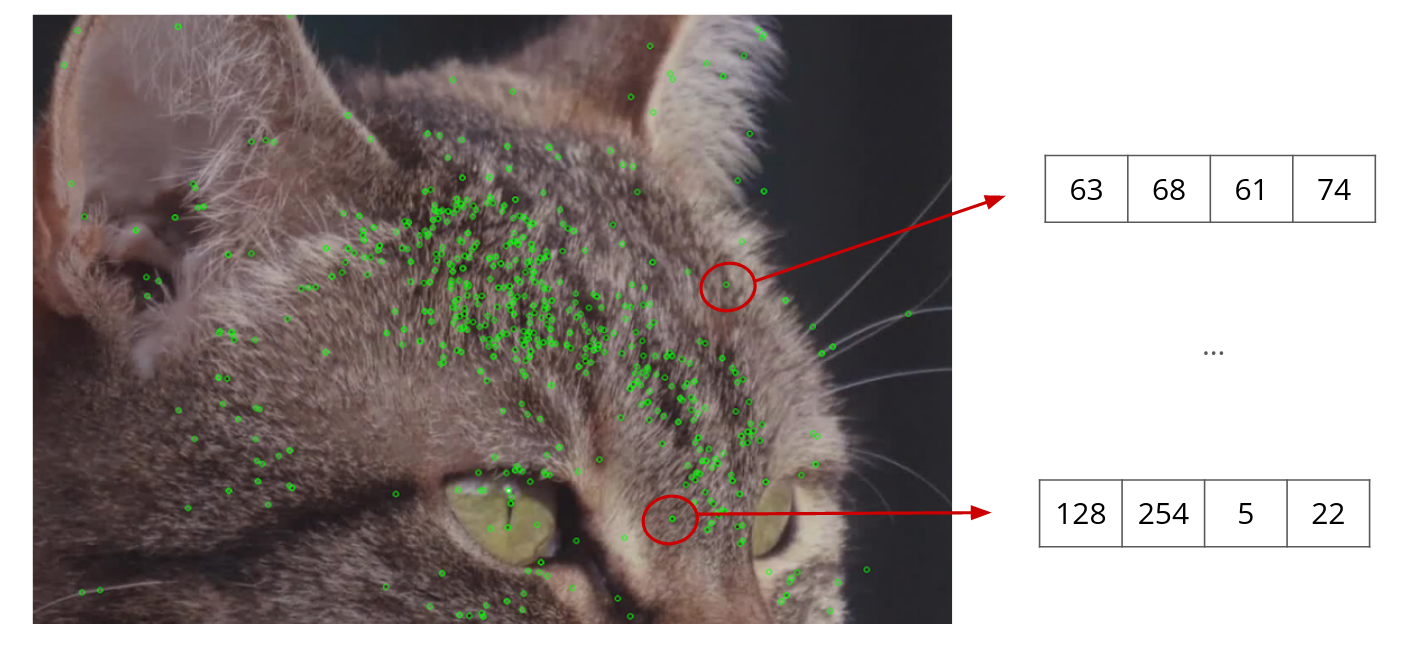
This protocol is reproduced for each image: the feature vectors will then be compared between them, from one image to another.
Step 3. Feature extraction
When the vectors are similar, it is a “match”: features from the first image are identified in the second image. If enough matches are found, it is then possible to estimate the geometric transformation that took place between the features that “matched”.

Direct application of feature extraction
Feature extraction allows to detect objects in images: if there are enough matches between two images, it means that the same object is in both images. It is in fact possible to realize augmented reality applications (without requiring either localization or mapping) directly using feature extraction, such as replacing an object by a video…
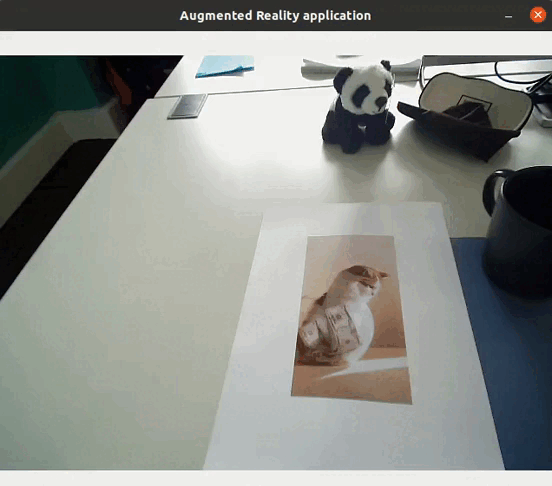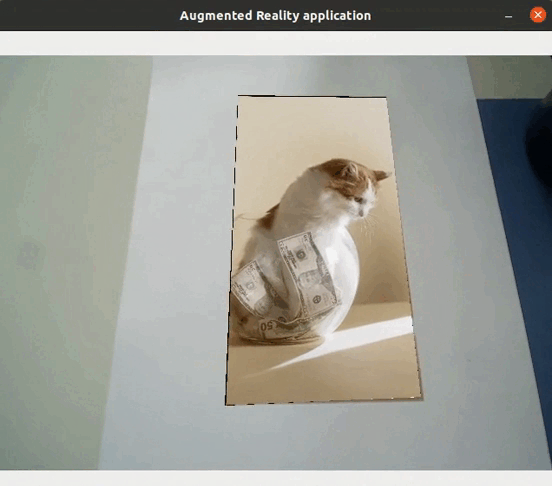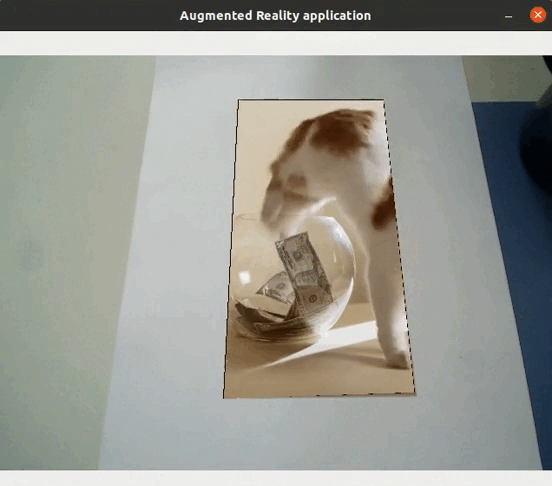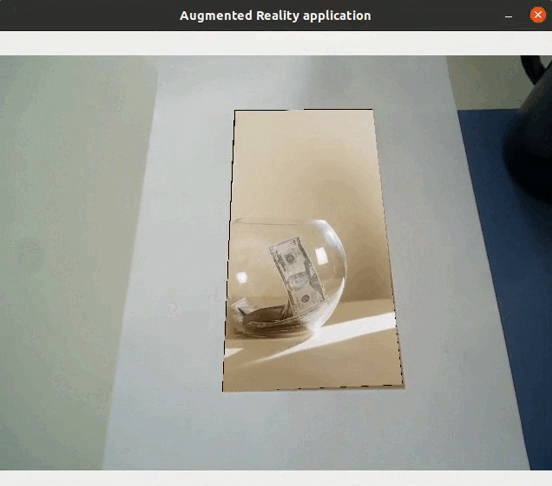
Application to visual SLAM
In addition, in the context of visual SLAM, the extraction of features on successive images from a video stream allows to compute the successive transformations that take place during the movement of a camera. It is then possible to track the movement of the camera in 3D. Moreover, the detected and matched features are then used to map and localize the camera in the constructed map (or the robot carrying this camera!).
IN BRIEF
To summarize, feature extraction corresponds to a subpart of visual SLAM, which allows the robot to build maps and to localize itself within these maps, as well as to easily do augmented reality.
You have a project related to SLAM or visual SLAM? The Awabot Intelligence team has the know-how and complementary skills to cover all the issues related to robotics. Contact us now.

