

A l’instar du SLAM (simultaneous localization and mapping), le SLAM visuel est une technologie basée sur des caméras, permettant à un robot mobile de pouvoir construire une carte de son environnement et de se localiser dans cette même carte. Celle-ci se distingue néanmoins par la variété de ses applications, qui ne se limitent pas à la navigation autonome. En effet, le SLAM visuel est aussi la base de la réalité augmentée. Explications
Rappel : les technologies SLAM au service des robots mobiles & AMR
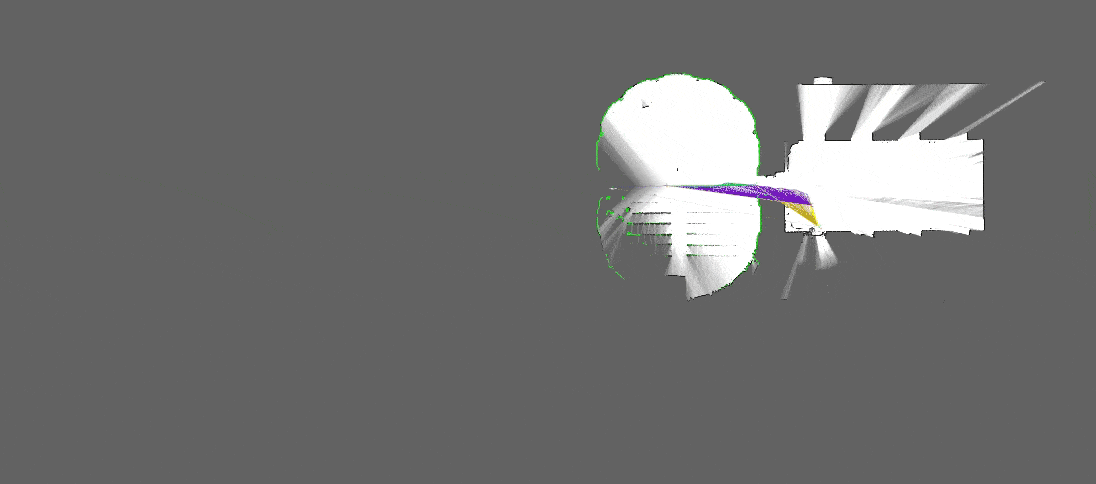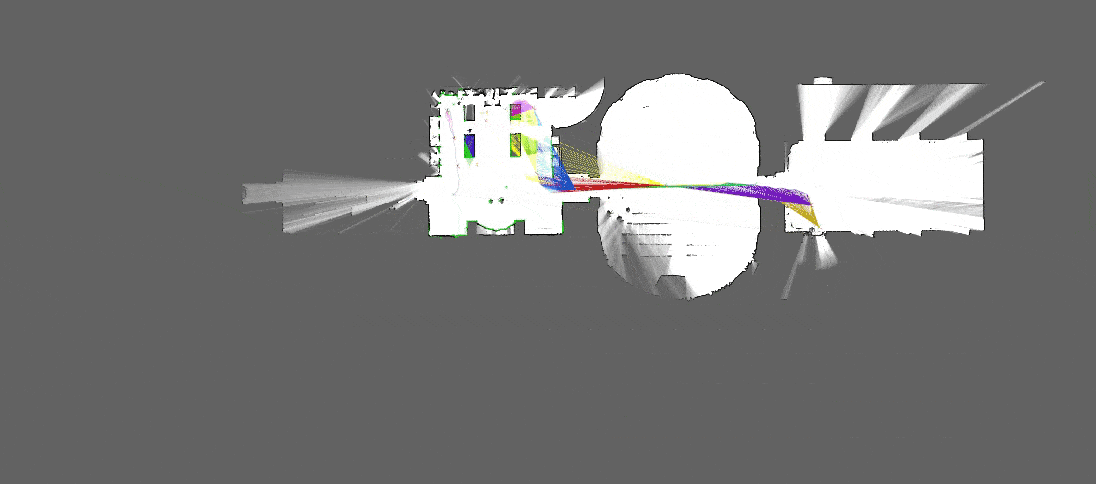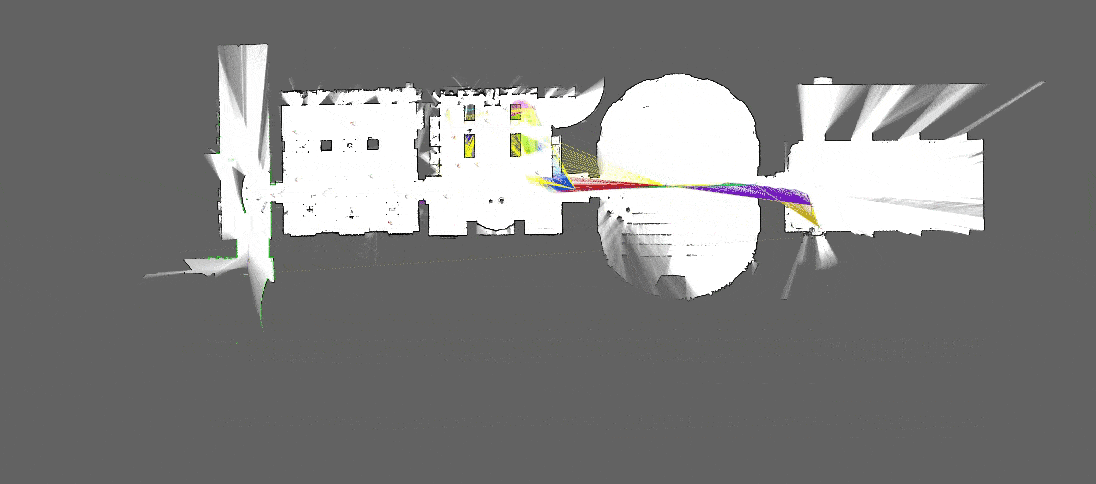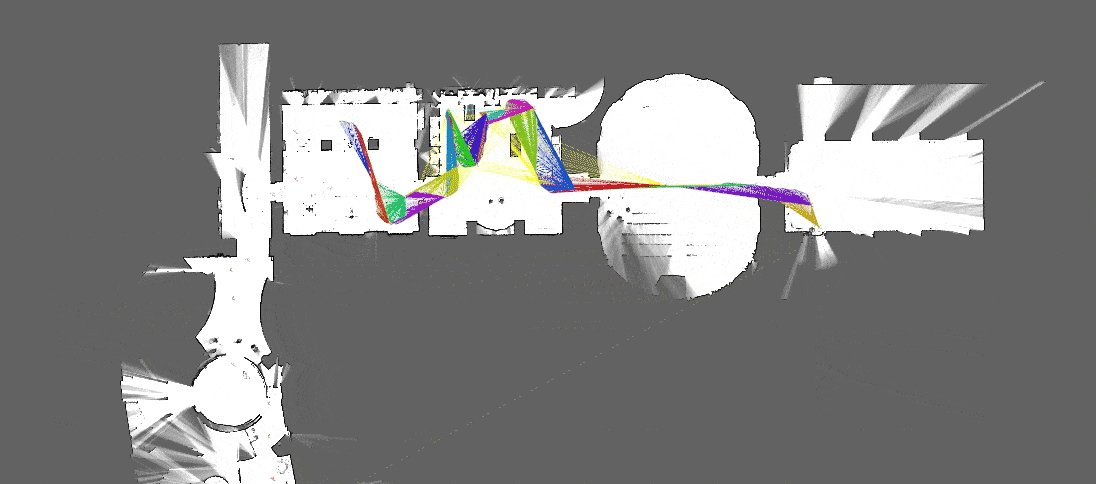
[Source : Google Cartographer]
Pour pouvoir construire une carte et se localiser avec fiabilité, un robot mobile a besoin d’informations concernant son environnement. Celles-ci s’obtiennent :
- soit par des capteurs de distance, tels que le LiDAR, qui émet une lumière et calcule le temps de retour après avoir été réfléchi par un objet, dans le but de déduire la distance entre le robot et l’obstacle.
- soit par des caméras, telles que de simples webcams d’ordinateur ou des caméras RGB-D, sur lesquelles se base le SLAM visuel.
SLAM visuel : quel intérêt pour un robot mobile ?
La force de cet algorithme réside dans le grand nombre d’informations obtenues : en effet, les images permettent d’estimer non seulement la distance du capteur aux obstacles mais aussi, les couleurs ou encore l’intensité de tous les pixels qui la composent. Ainsi, la cartographie recueillie grâce au SLAM visuel apparaît bien plus riche en informations comparativement à une carte résultant uniquement de capteurs de distance. De plus, les caméras (RGB, RGB-D) ont actuellement un coût matériel relativement faible par rapport aux LiDARS, qui ont cependant l’avantage d’être plus précis pour mesurer des distances.
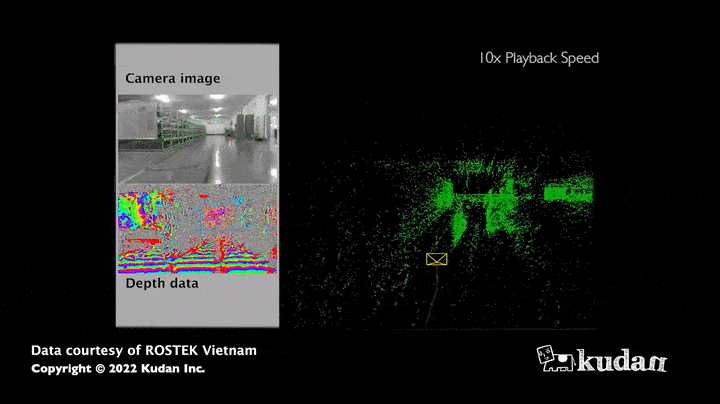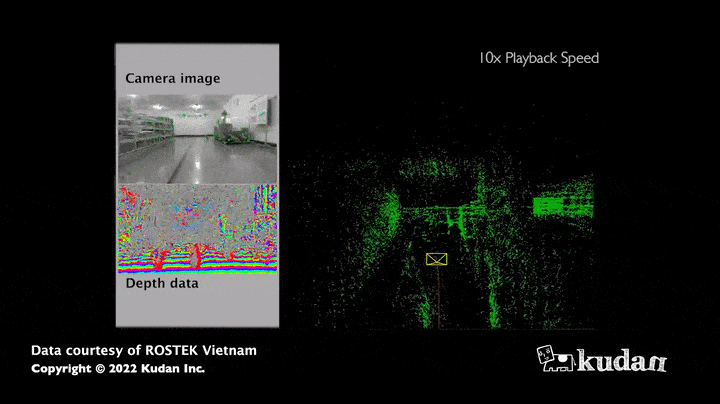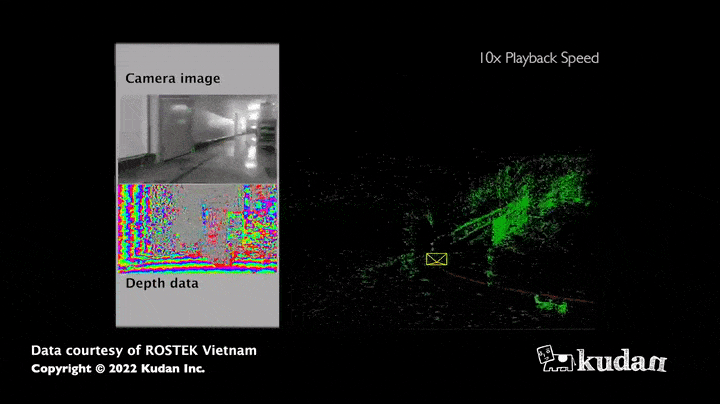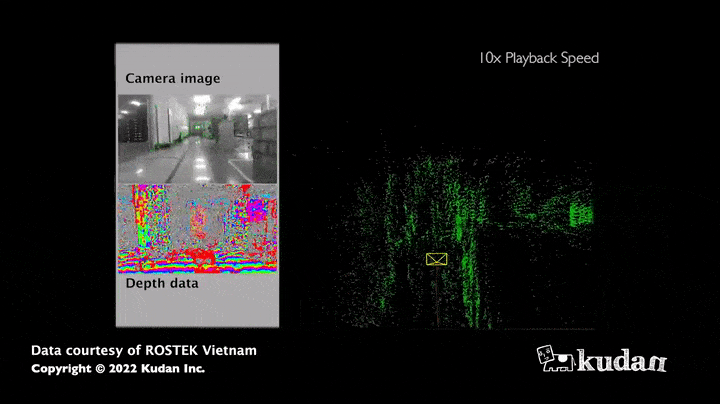
Cas d’usage du SLAM visuel
La navigation autonome
Les cartes obtenues grâce au SLAM visuel sont exploitées pour favoriser le déplacement d’AMR (autonomous mobile robots) : le principe est de donner une destination au robot, qui va alors définir sa trajectoire et s’y rendre de façon fiable et autonome en observant son environnement à l’aide de ses capteurs.

La réalité augmentée
Le principe ? Intégrer des objets virtuels dans un environnement réel. Et pour cela, le SLAM visuel représente un élément essentiel. Il permet de positionner des objets à un endroit et de pouvoir les retrouver lors d’une future visite, que ce soit à l’aide d’un téléphone, d’une webcam, ou encore (bientôt !) d’un robot de téléprésence.

SLAM visuel : l’extraction de caractéristiques au service de la réalité augmentée
Structure simplifiée d’un algorithme de SLAM visuel

Point de départ de la cartographie, les images issues de la caméra permettent d’estimer la position du robot dans cette carte : cela s’effectue grâce au module de localisation et de cartographie.
Pour aboutir à un résultat dans un cadre de SLAM visuel, ces deux modules ont besoin de recourir à une étape préalable appelée extraction de caractéristiques (les puristes du SLAM visuel comprendront ici notre besoin de simplification drastique de la taxonomie des méthodes existantes dans un cadre de vulgarisation). La suite de cet article vise à présenter cette étape.
En outre, pour comprendre les concepts de localisation et de cartographie, consultez notre étude comparative des technologies SLAM basées LiDAR.
Focus sur l’extraction de caractéristiques
Pour une compréhension en douceur, l’équipe Awabot Intelligence vous propose une explication étape par étape à base… de chats.
Étape 1. Détection de features
Les caractéristiques, ou “features”, sont des zones intéressantes, facilement détectables et spécifiques dans une image : elles sont extraites, puis suivies d’image en image, afin d’estimer le mouvement de la caméra et in fine, sa position, tout en construisant la carte simultanément. Elles peuvent correspondre à des points, des textures, des contours, qui se caractérisent par de forts changements de contrastes et de lumières.
Ainsi, à partir d’une image, la première étape consiste à les identifier en utilisant des algorithmes.

Étape 2. Description des features
Une fois que les features sont détectées, il convient alors de les décrire : pour chaque feature correspond un vecteur, à savoir un tableau de nombres qui va décrire une zone de l’image (la caractéristique). Ce tableau de nombres est lui aussi obtenu à l’aide d’un algorithme dont le but est de rendre la description robuste à certaines variations, telles que la rotation dans le plan ou les changements de luminosité. Cette description est fondamentale pour différencier toutes les features contenues dans une image.
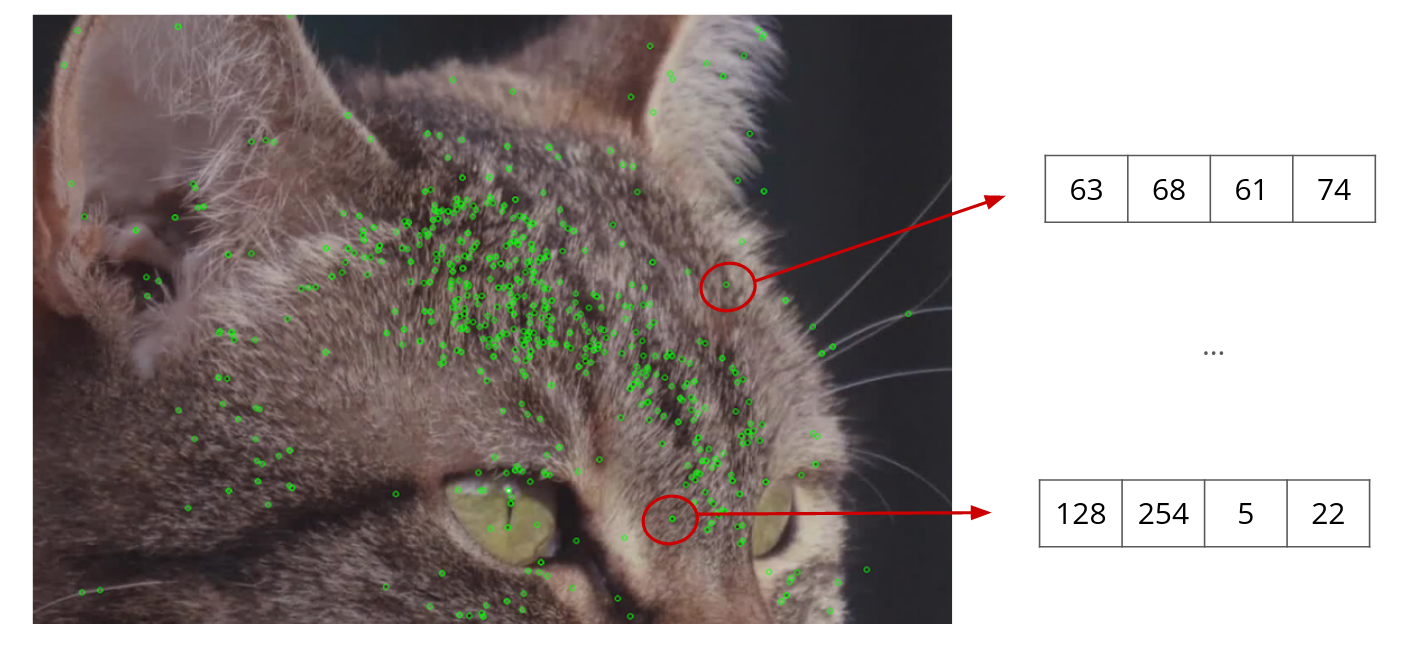
Ce protocole est reproduit pour chaque image : les vecteurs des features vont alors être comparés entre eux, d’une image à l’autre.
Étape 3. Extraction de features
Lorsque les vecteurs sont similaires, il s’agit alors d’un “match” : des caractéristiques de la première image sont identifiées dans la seconde image. Si suffisamment de matchs sont trouvés, il est alors possible d’estimer la transformation géométrique qui a eu lieu entre les éléments qui ont “matché”.

Application directe de l’extraction de caractéristiques
L’extraction de caractéristiques permet ainsi de détecter des objets contenus dans des images : s’il y a suffisamment de matchs entre deux images, cela signifie qu’un même objet se trouve dans les deux images. Il est de fait possible de réaliser des applications de réalité augmentée (sans nécessiter ni localisation ni cartographie) directement à l’aide de l’extraction de caractéristiques, telles que remplacer un objet par une vidéo…
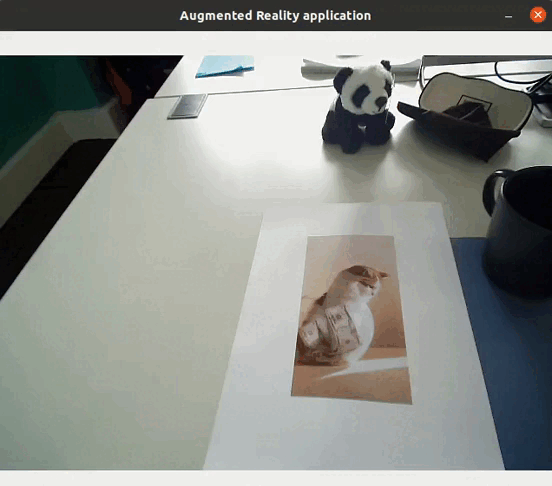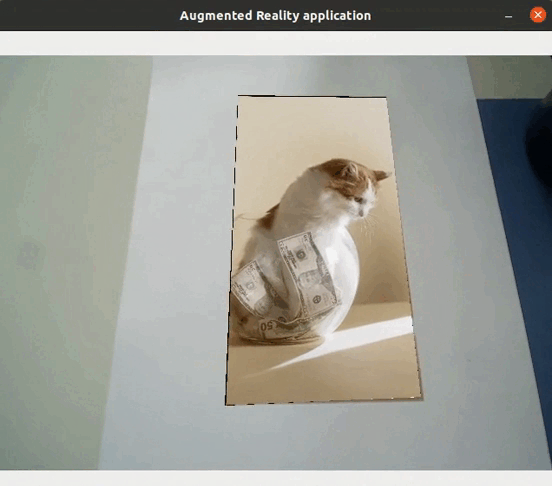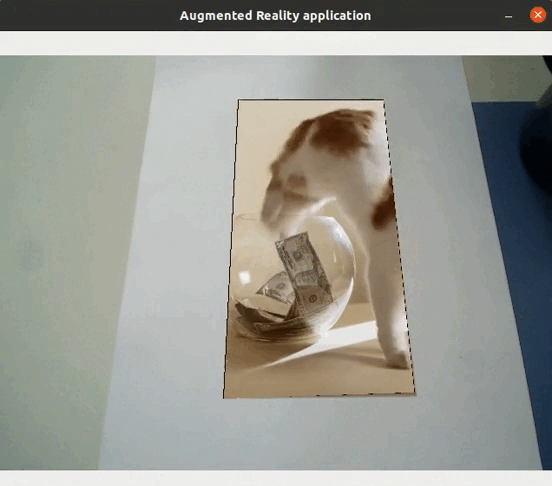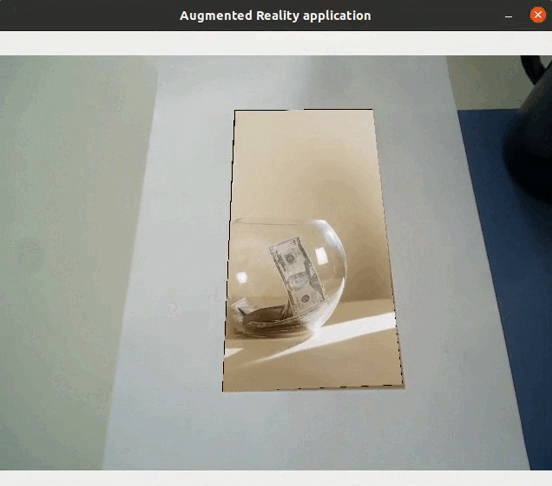
Application au SLAM visuel
De plus, dans le cadre du SLAM visuel, l’extraction de caractéristiques sur des images successives issues d’un flux vidéo permet de calculer les transformations successives qui ont lieu lors du déplacement d’une caméra. Il est alors possible de réaliser un suivi du mouvement de la caméra en 3D. De plus, les features détectées et mises en correspondance sont ensuite utilisées pour réaliser la cartographie et la localisation de la caméra dans la carte construite (ou du robot qui porte cette caméra !).
EN BREF
Pour résumer, l’extraction de features correspond à une sous-partie du SLAM visuel, qui permet aussi bien au robot de construire des cartes et de se localiser au sein de ces cartes, que de faire de la réalité augmentée facilement.
Vous avez un projet lié au SLAM ou au SLAM visuel ? Dotée de savoir-faire et compétences complémentaires couvrant l’ensemble des problématiques liées à la robotique, l’équipe Awabot Intelligence vous accompagne. Contactez-nous dès maintenant.

