

After having defined the foundations of autonomous robotic exploration versus tele-operation in a first article, the Awabot Intelligence team invites you to discover the different existing methods, as well as a comparison to identify the most efficient.
Mobile robotics: presentation of autonomous exploration methods
The subject of autonomous exploration has been studied extensively in recent years, and there is an abundance of research to identify the most commonly used methods. Thus, four main categories of methods stand out today.
Random method
Among the first methods of autonomous exploration is the random strategy. In this approach, the robot chooses its next position at random on the map, until it has explored the entire environment. This method is inefficient in terms of time since the next destination will not necessarily allow the robot to discover new areas of its environment. In addition, the next destination may be on an obstacle, in which case the robot cannot plan a path. If the position is not reachable (e.g., obstacle detected by a sensor), the robot will choose a new random position.
Method based on borders
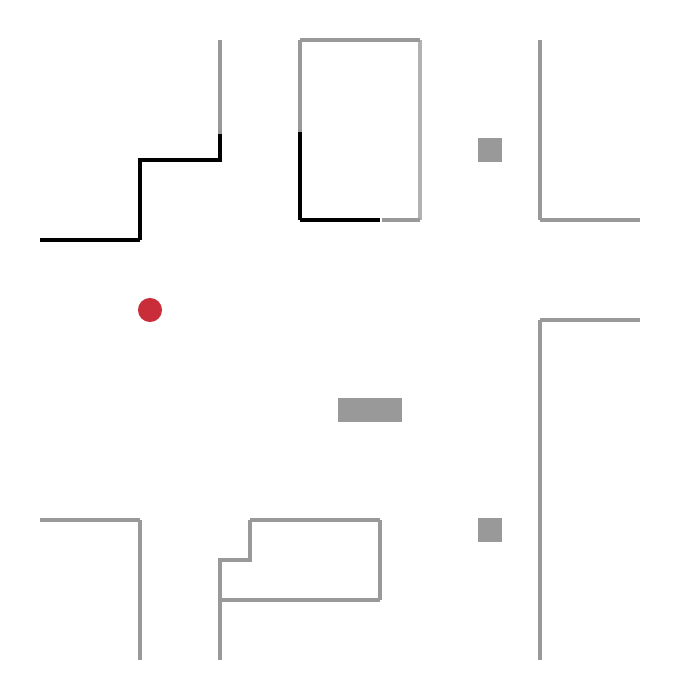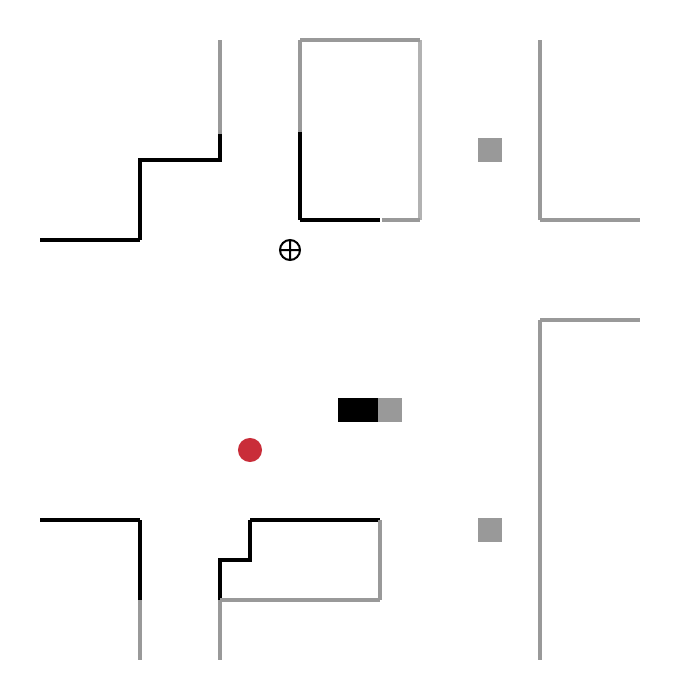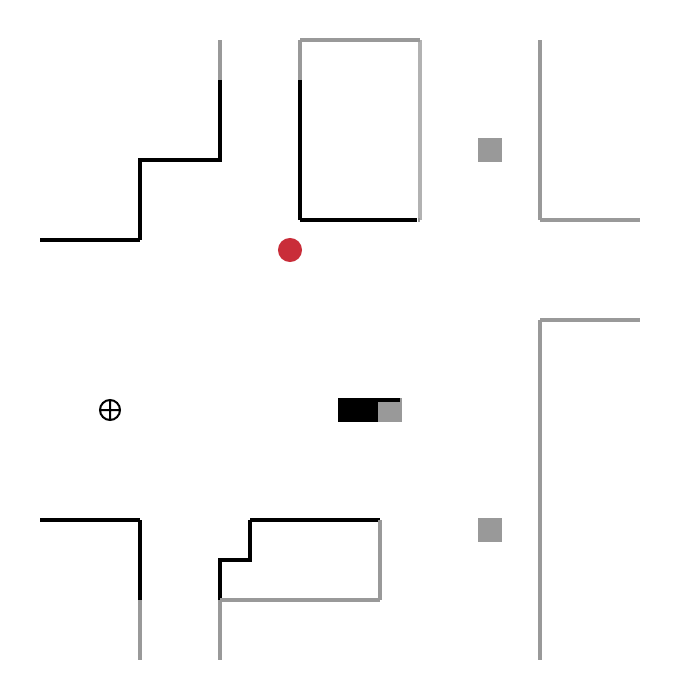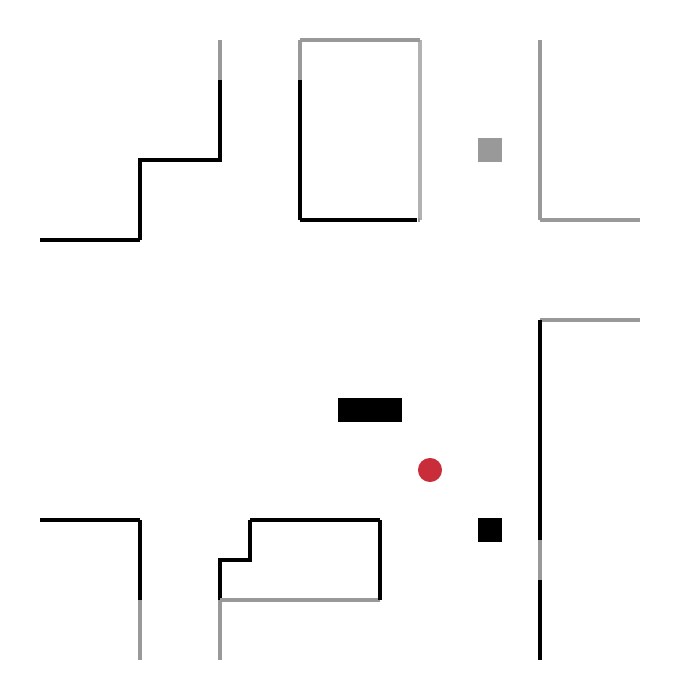
For this category of methods, the robot’s next destination is no longer random but lies on a border, a concept initially introduced by Yamauchi et al. in 1997. A border marks an area known to the robot from an unknown area. The robot explores the environment, continuously moving towards new frontiers.
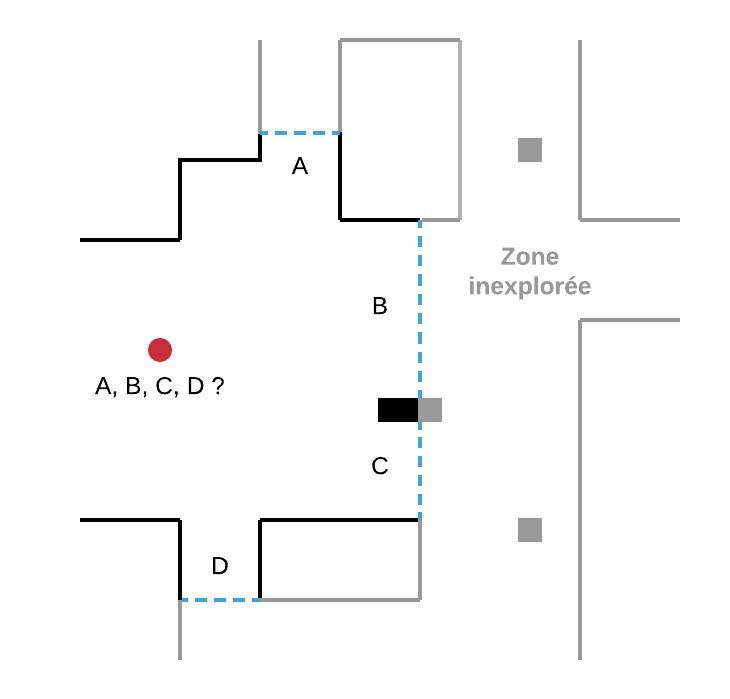
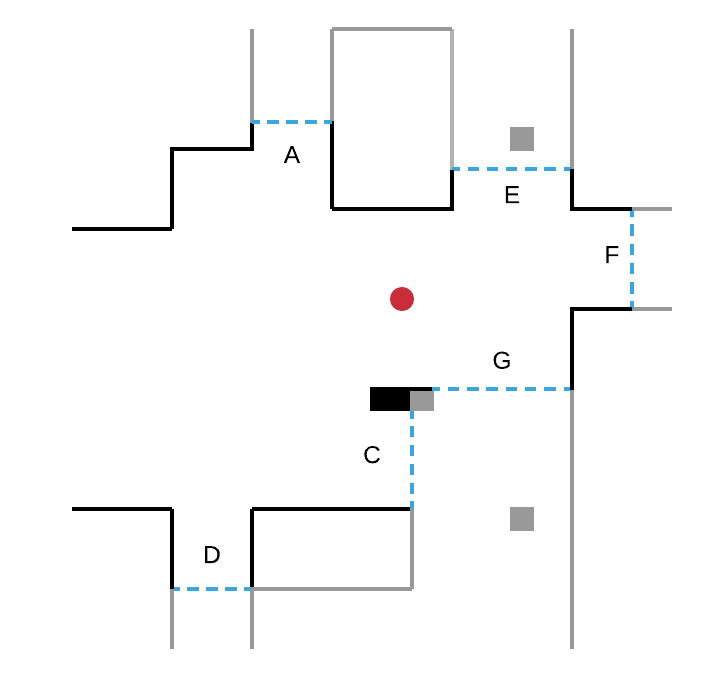
In the figure below, the robot (red circle) detects four boundaries A, B, C, D:
- moving towards border B, he discovers a new area of the environment;
- then, from its new position, it detects new borders E, F, G and will move towards one of them.
This process is repeated until the robot no longer detects any border. The exploration is then complete.


Méthod based on sampling
To explore an environment, sampling-based methods evaluate the next path the robot will take, and not the next position as in boundary-based methods.
These methods are based on the Rapid Exploration Random Tree (RRT) algorithm, widely used in path planning in mobile robotics. This algorithm consists of randomly building a tree by filling the known space of the robot. A tree represents a set of points, called nodes, connected by edges:
- here, a node corresponds to a position in the map;
- an edge is the path to get to this node.
For a finite number of iterations, the tree is built randomly starting from the initial position of the robot. For each branch of the tree, the amount of unexplored space on that path is calculated. The robot will choose the most interesting branch of the tree, that is, the one that allows it to discover the most unexplored space. Its next position will be a node of this branch. A new tree is then built from its new position. The process is repeated until you have explored the entire environment.

To the left, 45 iterations, to the right, 390 iterations.
Viewing an RRT graph
[SOURCE : Wikipedia]
It is also possible to combine the sampling-based method with the border-based method:
- select borders as future candidate positions,
- extend a tree to these positions,
- then choose the most interesting branch of the tree.
Method based on learning
Learning-based methods have developed in robotics in recent years. In particular, reinforcement learning is a method of machine learning that involves letting the algorithm learn from its own mistakes. This approach is inspired by the fundamental way humans and animals learn.
For this, the robot chooses to perform an action. In autonomous exploration, an action corresponds to the selection of a position to reach in the map. By choosing a position, he gets a reward. A reward is a positive or negative gain that measures the success or failure of an action. By repeating experiments (ie, set of successive actions with rewards) within a simulation environment, the robot will be able to optimize the algorithm (eg, a neural network) choosing the next action to be performed in order to maximize the rewards obtained. Based on this principle, it is then possible to formulate a system for teaching the robot to perform a task, such as determining the next most interesting position.
For example, the robot may be penalized if the next chosen destination is in unknown space or too close to an obstacle. Indeed, selecting a destination in unknown space is dangerous since it can be an obstacle. The robot can, however, be rewarded if it discovers new areas of its environment.

[Li et al., “Deep Reinforcement Learning based Automatic Exploration for Navigation in Unknown Environment”. 2020.]
Mobile robotics: comparison of autonomous exploration methods
In order to identify the most efficient method, here is a comparative table based on different criteria:
- ease of implementation: this is assessed in relation to the available and functional source code;
- widespread use in self-exploration: judged by results presented in recent research articles;
- effectiveness of the method: also judged on the basis of the results presented in recent research articles.

0: not at all compatible
1: not very compatible
2: compatible
Another important point in the selection of the reference method: the fact that it is quickly compatible with the software tools used by Awabot Intelligence, and sufficiently understandable and easy to modify in order to be able to adapt it, if necessary, to various contexts of use.
Thus, it is the boundary-based method that accumulates the greatest number of points and stands out as the reference method. Indeed, even if it seems less effective than methods based on sampling or learning, its relative ease of implementation and its popularity in autonomous exploration allow it to stand out.
But how to implement the method based on borders? See you in september to find out in the third article of our series dedicated to autonomous exploration for mobile robotics.


{kind=link}
{kind=link}