

Second volet de la série d’articles consacrée à l’exploration autonome au service des robots mobiles. Après avoir défini les fondements de l’exploration robotique autonome versus la télé-opération, l’équipe Awabot Intelligence vous propose de découvrir les différentes méthodes existantes, ainsi qu’un comparatif permettant d’identifier la plus efficiente.
Robotique mobile : présentation des méthodes d’exploration autonome
Le sujet de l’exploration autonome a été particulièrement étudié ces dernières années et foisonnent de travaux de recherche permettant d’identifier les méthodes les plus utilisées. Ainsi, quatre grandes catégories de méthodes se distinguent aujourd’hui.
Méthode aléatoire
Parmi les premières méthodes d’exploration autonome, on trouve la stratégie aléatoire. Dans cette approche, le robot choisit sa prochaine position aléatoirement dans la carte, jusqu’à avoir exploré l’environnement en entier.
Cette méthode est inefficace en termes de temps puisque la prochaine destination ne va pas forcément permettre au robot de découvrir de nouvelles zones de son environnement. De plus, la prochaine destination peut se trouver sur un obstacle, auquel cas le robot ne peut pas planifier un chemin. Si la position n’est pas atteignable (e.g., obstacle détecté par un capteur), le robot choisira une nouvelle position aléatoire.
Méthode basée sur les frontières
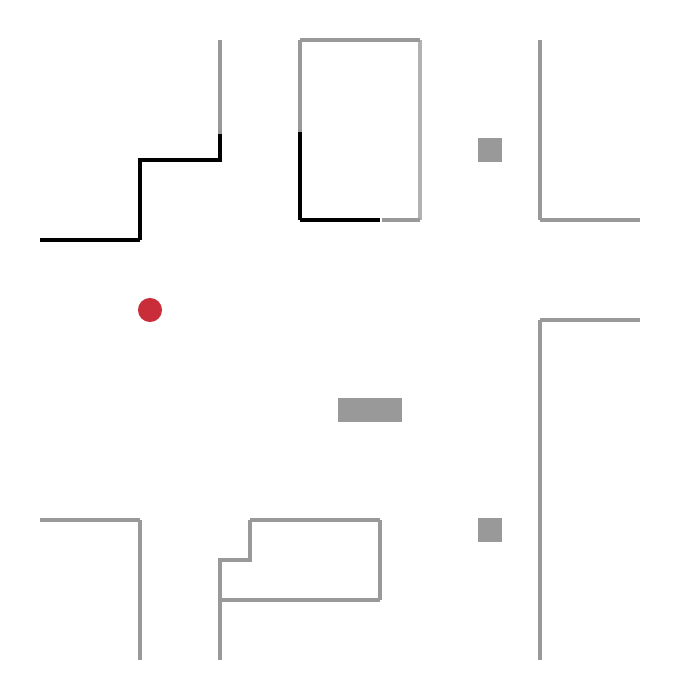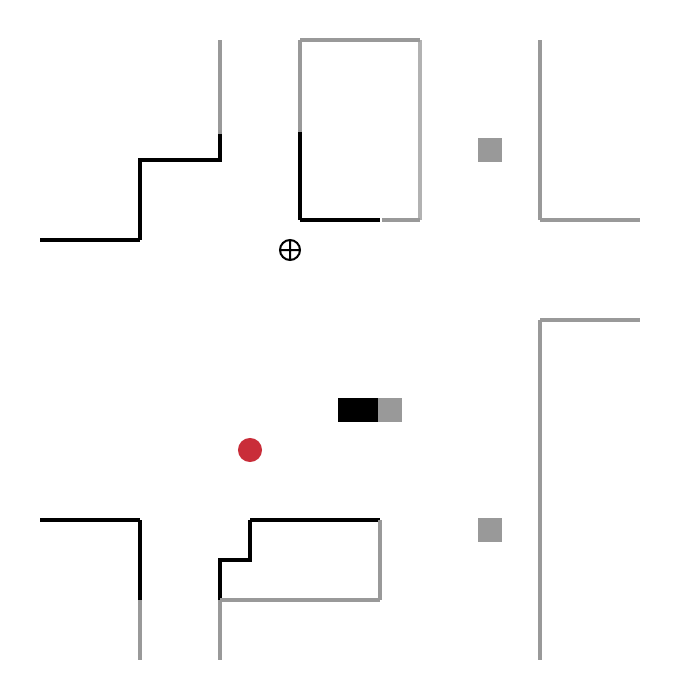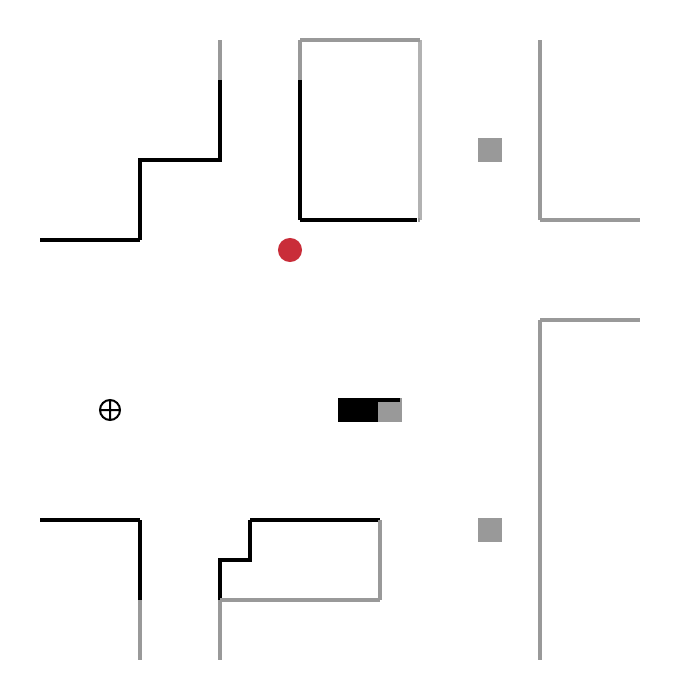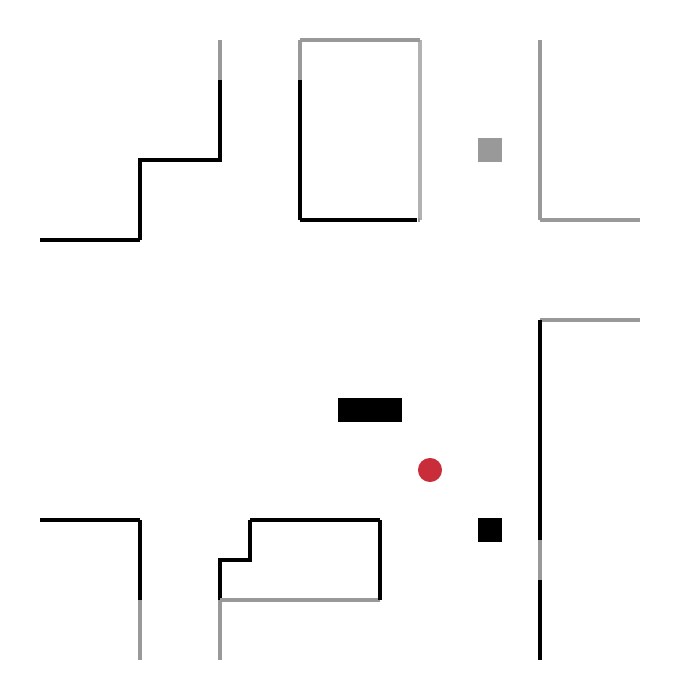
Pour cette catégorie de méthodes, la prochaine destination du robot n’est plus aléatoire mais se trouve sur une frontière, concept introduit initialement par Yamauchi et al. en 1997. Une frontière délimite une zone connue par le robot, d’une zone inconnue. Le robot explore l’environnement en se déplaçant continuellement vers de nouvelles frontières.
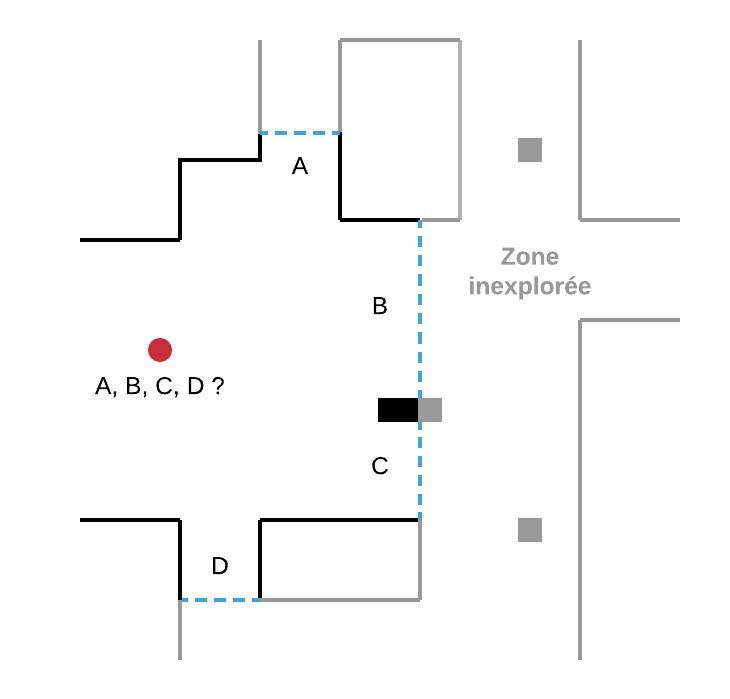
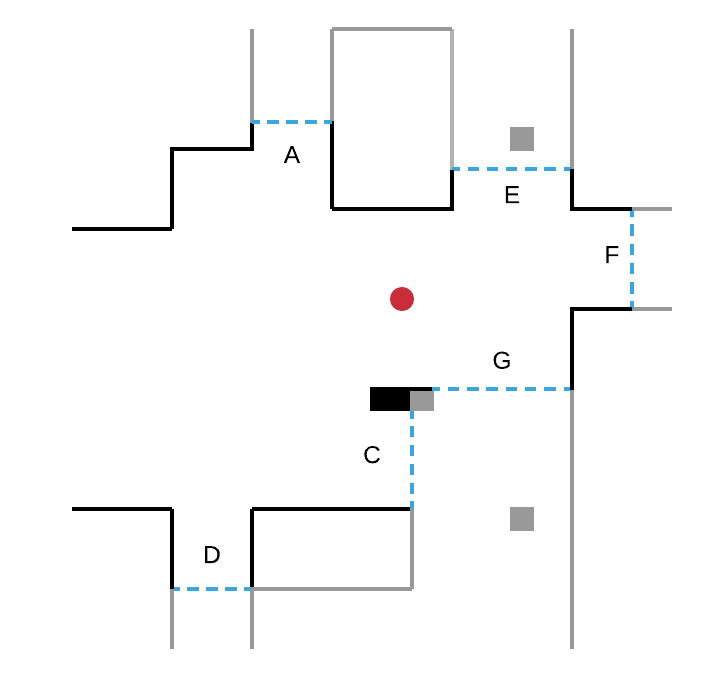
Sur la figure ci-dessous, le robot (cercle rouge) détecte quatre frontières A, B, C, D :
- en se déplaçant vers la frontière B, il découvre une nouvelle zone de l’environnement ;
- puis, depuis sa nouvelle position, il détecte de nouvelles frontières E, F, G et se déplace vers l’une d’entre elles.
Ce processus est répété jusqu’à ce que le robot ne détecte plus aucune frontière. L’exploration est alors terminée.


Méthode basée sur l’échantillonnage
Pour explorer un environnement, les méthodes basées sur l’échantillonnage évaluent le prochain chemin que le robot va emprunter, et non la prochaine position comme dans les méthodes basées sur les frontières.
Ces méthodes s’appuient sur l’algorithme de l’arbre aléatoire à exploration rapide (RRT), très utilisé dans la planification de chemin en robotique mobile. Cet algorithme consiste à construire aléatoirement un arbre en remplissant l’espace connu du robot. Un arbre représente un ensemble de points, appelés nœuds, reliés par des arêtes :
- ici, un nœud correspond à une position dans la carte ;
- une arête correspond au chemin pour aller jusqu’à ce nœud.
Pour un nombre d’itérations fini, l’arbre est construit de manière aléatoire en partant de la position initiale du robot. Pour chaque branche de l’arbre, la quantité d’espace inexploré sur ce chemin est calculée. Le robot va choisir la branche de l’arbre la plus intéressante, c’est-à-dire celle qui lui permet de découvrir le plus d’espace inexploré. Sa prochaine position sera un nœud de cette branche. Un nouvel arbre est ensuite construit à partir de sa nouvelle position. Le processus est répété jusqu’à avoir exploré l’environnement en entier.

À gauche, 45 itérations, à droite, 390 itérations.
Visualisation d’un graphe RRT
[SOURCE : Wikipedia]
Il est également possible de combiner la méthode basée sur l’échantillonnage avec celle basée sur les frontières :
- sélectionner des frontières comme futures positions candidates,
- étendre un arbre jusqu’à ces positions,
- puis choisir la branche de l’arbre la plus intéressante.
Méthode basée sur l’apprentissage
Les méthodes basées sur l’apprentissage se sont développées ces dernières années en robotique. En particulier, l’apprentissage par renforcement est une méthode d’apprentissage automatique qui consiste à laisser l’algorithme apprendre de ses propres erreurs. Cette approche s’inspire de la manière fondamentale dont les humains et les animaux apprennent.
Pour cela, le robot choisit d’effectuer une action. Dans le cadre de l’exploration autonome, une action correspond à la sélection d’une position à atteindre dans la carte. En choisissant une position, il obtient une récompense. Une récompense est un gain positif ou négatif qui mesure le succès ou l’échec d’une action. En réitérant des expériences (i.e., ensemble d’actions successives avec récompenses) au sein d’un environnement de simulation, le robot va pouvoir optimiser l’algorithme (e.g., un réseau de neurones) choisissant la prochaine action à réaliser dans le but de maximiser les récompenses obtenues. En se basant sur ce principe, il est alors possible de formuler un système pour apprendre au robot à réaliser une tâche, telle que déterminer la prochaine position la plus intéressante.
Par exemple, le robot peut être pénalisé si la prochaine destination choisie est dans l’espace inconnu ou trop proche d’un obstacle. En effet, sélectionner une destination dans l’espace inconnu est dangereux puisque cela peut être un obstacle. Le robot peut en revanche être récompensé s’il découvre de nouvelles zones de son environnement.

[Li et al., « Deep Reinforcement Learning based Automatic Exploration for Navigation in Unknown Environment ». 2020.]
Comparaison des méthodes d’exploration autonome
Afin d’identifier la méthode la plus efficiente, voici un tableau comparatif s’appuyant sur différents critères :
- facilité de mise en œuvre : celle-ci est évaluée par rapport au code source disponible et fonctionnel ;
- utilisation répandue dans le cadre de l’exploration autonome : jugés au regard des résultats présentés au sein d’articles de recherche récents ;
- efficacité de la méthode : également jugés au regard des résultats présentés au sein d’articles de recherche récents.

0 : pas du tout compatible
1 : peu compatible
2 : compatible
Autre point ayant son importance dans la sélection de la méthode de référence : le fait que celle-ci soit rapidement compatible avec les outils logiciels utilisés par Awabot Intelligence, et suffisamment compréhensible et aisée à modifier afin de pouvoir l’adapter, le cas échéant, à divers contextes d’utilisation.
Ainsi, c’est la méthode basée sur les frontières qui cumule le plus grand nombre de points et s’érige en tant que méthode de référence. En effet, même si elle paraît moins efficace que les méthodes basées sur l’échantillonnage ou l’apprentissage, sa relative facilité de mise en œuvre et sa popularité dans l’exploration autonome lui permettent de se distinguer.
Mais comment mettre en œuvre la méthode basée sur les frontières ? Rendez-vous début septembre pour le découvrir dans le troisième volet de notre série d’articles consacrés à l’exploration autonome au service de la robotique mobile.


{kind=link}
{kind=link}